Overcomplicating Things for Fun
I mentioned in passing I did something fiddly for fun:
I've built the world's most over-complicated thermometer using a @Raspberry_Pi + Sense Hat + Kinesis Firehose + AWS Lambda + @HostedGraphite
— Michael Twomey (@micktwomey) October 23, 2015
While that tweet pretty much sums up what I did I thought I'd go into a little bit more detail on how I built a thermometer using only the hardware and software I had immediately to hand: a Raspberry Pi, a Sense Hat, an AWS account and a Hosted Graphite account.
First, I didn't just do this for fun, I also wanted to kick the tyres of a couple of new services. I find the best way to evaluate some services is to find a little noddy task you can leave running for weeks and see what it looks like after a while. In this case I wanted to see was what the AWS Kinesis Firehose and Lambda services were like.
Recording the Data
The first step is recording the data. I used Python 3, the sense_hat module and the boto3 library. The latter deserves a special mention, it's a complete rewrite of Boto using automatically generated code. It tracks the AWS API really closely and seems to be more consistent overall (due to being generated).
I basically loop forever, reading the sensors, stashing to disk and pushing to Firehose.
An important bug is in this code: I've forgotten to append a separator (e.g. \n) to each JSON blob I push to Firehose, they all just run together in the S3 blob. While Firehose won't break an individual data blob you push, it's your responsibility to make sure you can split them up :) When I was testing with jq I didn't notice this as jq handles this just fine (spotting the end of one JSON blob and the start of another). Python's JSON library wants only one blob per file and gets happy. You can see how I dealt with this later.
Configuring Firehose
Not too much to say here, I set it to write to a S3 bucket every so often. It just works :)
If you're really curious here's a dump of the config:
Processing the S3 Blobs
To process a blob I created a Python 2.7 Lambda function. Configuring mostly involved pointing at the bucket and handling all events. Then I uploaded my function as a zip.
Uploading by hand is annoying so I use a Makefile to upload:
So now I can use "make upload" to zip up change and update the Lambda function.
The code itself:
Mostly it's derived from the sample code you get when you create the Lambda function, plus a bit to push to the statsd in Hosted Graphite.
There are two things to note:
- Python 2.7's in-memory gzip handling was so annoying I just wrote to disk and read it back again. Python 3 has a neater gzip.decompress function.
- I had to write a little noddy function to spot the JSON blobs and emit for parsing by the json library. This is due to me forgetting a separator earlier :)
TBH I wish the python json.load function could handle multiple blobs, maybe an iterload which yielded each JSON blob. I know it's not strictly speaking correct but it'd be handy here :)
Hosted Graphite
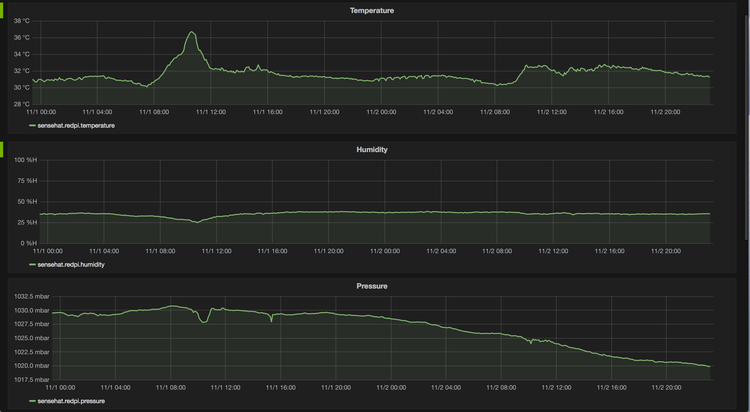
Finally, the code pushes to Hosted Graphite where I graph the results:
Addendum: Hardware
Now, you may be wondering how we work in such a sweltering office. Well, really you've found a problem with the setup. The Pi itself generates quite a bit of heat (I suspect it's due to it being a Pi 1 and not a Pi 2, so it might run a bit hotter to get the job done), so what you are really seeing is a measurement of the heat of the Pi plus a bit from the office. That 5℃ shift really does look like a genuine bit of overheating in the office though :)
Next up: add a cable to the GPIO header to move the sense hat away and get a more realistic measure. Alternatively I might look at measuring the Pi itself and subtracting that.
Fun Things I've Learned
- Always use a separator for Firehose data. Rather than \n I'd recommend going all old school and using the original ASCII separator: \x1e. You can even throw in start of record to make sure you can skip corrupted records. Bet you didn't know about those characters :)
- Firehose itself is super simple to use. I can see myself just throwing lots of crap into there and sorting it out later. It can encrypt data at rest too, so you can log quite a bit in there if you want.
- Lambda is pretty cool about failures. At one point there was a problem talking to Hosted Graphite (or S3), so the Lambda functions kept timing out. For any given S3 PUT Lambda will keep retrying for up to 24 hours. In my case it kept retrying until it worked, so all my data got backfilled correctly. I didn't even notice from my temperature graphs, it was only when I looked in the Cloudwatch dashboard I realised there had been a problem. Idempotent for the win.
- Firehose and Lambda make for a pretty simple log processing pipeline, with some moderate fault tolerance.
- I didn't notice it but it'd be nice if there was a way to feed in sensitive vars into your Lambda function. I hope of removed all my keys in my Gist.
- The sense hat + Pi runs hot :)
The full gist of all the code can be found here.